ここまで見てきた xCORE-200 による組み込みソフトウェアの開発のメリットは、下記のURLで紹介しているハードウェアにより実現されています。
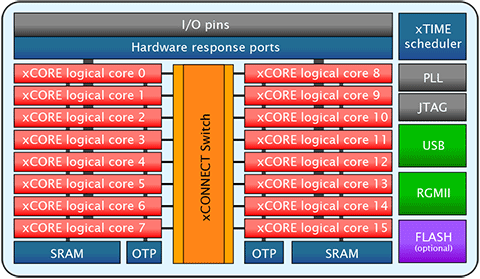
Source: www.xmos.com
ここでは、XMOS社が上記URLで紹介している資料を元に記載していきます。
1.各CPUを完全に並列に動作させる仕組み「xTIME scheduler」

これは、リアルタイムOSをハードウェア実装した部分に相当します。5段のパイプラインを、8個のCPUが共有する仕組みとなっています。5個までのCPUがアクティブになっている場合には、5サイクル毎に、自分のタスクの命令がパイプラインに発行されます。
基本的には、ラウンドロビン方式で各タスクの命令が順番に発行されていきますので、他のタスクの実行の完了を待つことなく、必ず自分のタスクが実行されていきます。
尚、このパイプラインは、500MHz で動作する Dual Issue の構造になっています。割り算以外の命令は全て1サイクル(500MHz)で完了するアーキテクチャになっています(64ビットの積和演算なども1サイクルで完了します)。
500MHzで動作する5段のパイプラインに、5〜8サイクル毎に自分の命令が発行されることから、分岐予測は不要になります。このため分岐予測ミスによるペナルティも発生しません。
500MHzで動作する5段のパイプラインに、5〜8サイクル毎に自分の命令が発行されることから、分岐予測は不要になります。このため分岐予測ミスによるペナルティも発生しません。
2.各タスク (CPU) が直接、データを送受信する仕組み「xCONNECT」

xCORE-200 アーキテクチャでは、各CPU が 32bitのレジスタセットを持っています。そして、各CPUは、 共有メモリを介さずに、直接データを送受信するための仕組み xCONNECT があります。
この xCONNECT を利用するための xC 記述が Channel 変数になります。この Channel 変数に値を出力すると、その値が、接続された他方のCPUに、xCONNECTを介して送られます。
この xCONNECT を経由して行われるデータのやり取りは、"IN", "OUT" 命令で実現され、CPUのレジスタの値を送信する、又は、データをレジスタに受信します。
この仕組みにより、容易にソフトウェア・パイプラインを構築することが可能です。
3.ポート処理をオフロードできるインテリジェントなハードウエア・レスポンス・ポート

各物理ポート毎に、上記のロジックがあります。このロジックを使用することで、ポートに関する処理を、CPUで動作するタスク処理からオフロードすることができます。
例えば、FIFO を使用して、CPUから32bit データを 1 ビット出力する「パラレル・シリアル変換」を行うことが可能です。この場合、CPUからは32bit データを 1 サイクルでポート側に渡します。CPU側のタスクはすぐに次の処理を実行できます。一方、ポート側では、設定されたクロック毎に32ビットデータをシフトして出力していきます。ポートの処理をCPU側の処理と分離・オフロードできます。
また、Port Counter を使用して、「Counter 値がある値になったときに、FIFOのデータを出力する」といった制御も可能です。
加えて、そのポートがどのクロックに同期して動作するかも、設定することができます。
このポートに関する設定については、XMOS Programming Guide に詳しく説明がありますので、ご参照ください。
4.高性能メモリ・システム

このページで最後に紹介するのが、高性能メモリ・システムです。
リアルタイム処理に有効となるアーキテクチャとなっています。キャッシュを持たず、1 cycle でアクセス可能です。Tile内の全てのCPU(8個のCPU)からのアクセスも可能で、共有メモリ領域を持つことも可能です。
以上、ここまで簡単に、xCORE-200 のハードウエアについて見てきました。ここまでの説明で、xCORE-200 による組み込みソフトウェア開発のメリットをご理解頂けたと思います。
XMOS社では、xCORE-200 のハードウエアのみならず、xCORE-200 上で動作するソフトウェアを提供しています。
最近では、Audio 向けの Reference Software だけでなく、Voice Interface Solution として、アレイ・マイクロフォン向けの Reference Software も提供しています。
XMOS 社の提供する Solution についても、是非ご確認頂ければと思います。
(その他の投稿については、右上の「ページ」をご確認ください)
0 件のコメント:
コメントを投稿